提升用于Python量化交易模型的股票数据
假设你计划构建自己的算法交易模型。
你很可能只使用价格(收盘价)数据来训练你的模型和算法,但很快你就会发现,你的模型表现不佳。
你很快会使用典型的 OHLCV 数据(开盘价、最高价、最低价、收盘价、成交量),这已经有所改进,但模型似乎仍然不够出色。
你能做些什么?
可参考的 Colab 笔记本: https://colab.research.google.com/drive/1ywqti1TuTDY_Z11ry0x4ITclCwxnXAeI?usp=sharing
要点:
https://gist.github.com/JustinGuese/019e0e71100abe6555f78c32fd0b10a9
机器学习交易机器人喜欢什么?
典型的机器学习算法只能处理它获得的数据。它(通常)不能创建新的特征或解释,例如“如果成交量增加,价格的三阶导数上升,价格更有可能上涨”,而是只能“观察”它获得的数据。这些将是诸如“如果价格超过 100 美元,成交量超过 2000,价格更有可能上涨”之类的计算。
机器学习新手现在正在尝试通过训练数十年或使用越来越多的 GPU 来解决这个问题,但一种更高效的方法是为算法提供额外的数据,以便它可以使用更多资源来推断计算。
可以通过以下方式实现:
- 获取更多数据(更长的时间跨度)
- 添加统计指标
- 添加你自己的信号和解释
实践:增强你的数据
第一步 - 获取你的数据
首先,让我们获取一些基本 OHLCV 数据。我喜欢 yfinance 模块,因为它非常简单。它无法与实时数据流相比,但另一方面,它免费且非常适合实验!
pip install yfinance pandas numpy matplotlib ta
导入 yfinance、Pandas、NumPy、Matplotlib 模块
import yfinance as yf
import matplotlib.pyplot as plt
import pandas as pd
获取一些股票数据,间隔和周期指的是时间范围。
interval 接受的值,例如 1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo
period 接受的值,例如 1d, 5d, 1mo, 3mo, 6mo, 1y, 2y, 5y, 10y, ytd, max
并非所有组合都适用,例如 1m(1 分钟)间隔最多只能与 7 天的数据一起使用,1h(1 小时)间隔最多只能与 3 个月的数据一起使用(需要写成 90d)。但我们先用每日数据来试验
df = yf.download("MSFT", period="5y", interval="1d")
df.head()
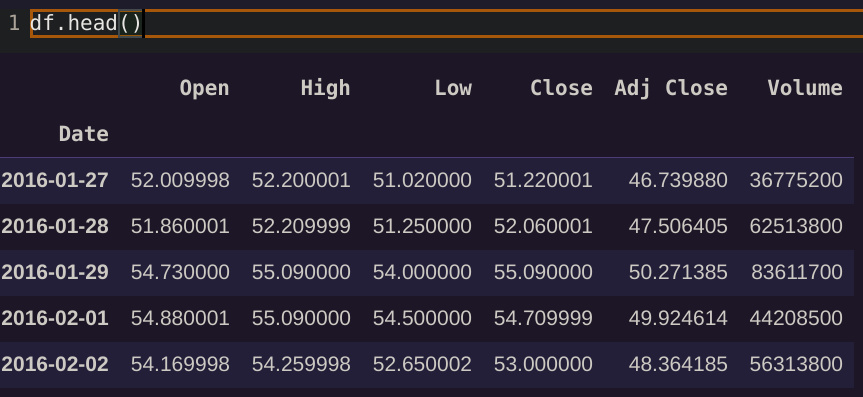
快速说明:什么是开盘价、最高价、最低价、收盘价、调整后收盘价和成交量?价格在哪里?
股市中没有“单一价格”!你可以将 OHLCV 数据想象成时间上的“桶”或“箱”,总结该时间窗口内发生的全部交易。你通常知道的典型“线”图通常指的是该股票在时间范围 X 内的“收盘价”,例如该股票在该时间范围收盘时的价值。
如果我们查看每日数据,“开盘价”指的是市场开盘时的平均股票价格,而“收盘价”指的是股票在市场收盘时的平均价格。如果查看每小时数据,“开盘价”指的是该小时的开始,例如上午 11 点,而“收盘价”指的是该小时的结束时间,例如上午 11 点 59 分 59 秒。
同样,“最高价”是该时间段内记录的最高交易/价格,“最低价”是最低价格。成交量指的是该时间段内交易的资产或股票数量。
这意味着如果例如,“最低价”和“收盘价”彼此接近,我们很可能看到下跌趋势,因为收盘价是当前的最低价。同样,如果成交量很高,则有很多交易正在进行,因此例如,如果成交量高于平常,则似乎市场上发生了某些事情。但无论如何,请参考https://www.investopedia.com/ 获取更多信息,现在我们将继续编码!
什么是“调整后收盘价”?
这很重要,因为大多数机器学习算法对“普通”收盘价数据感到非常困惑。如果股票分割,数据看起来像是价格出现了疯狂的下跌。
原因简单来说,如果股票过于昂贵,公司会决定将股票“分割”成两部分。这意味着我的投资减少了一半吗?当然不是,你只需获得两倍于你持有的股票,因此,在账面价值上,你仍然持有相同价值的股票。
有趣的是,分割通常会使价格上涨(人类是多么愚蠢!),如果你的机器学习算法看到价格大幅下跌,它很可能会卖掉所有股票。
因此,你应该始终使用“调整”后的值,可以想象成“清理”后的价格数据,考虑到分拆、股息以及所有不影响数据真实价值的其他事件。因此,请尝试始终将调整后的数据用于你的算法!
在 yfinance 的情况下,这很容易做到,因为我们可以使用“调整后收盘价”而不是“收盘价”。
绘制数据
查看数据,我们已经可以看到一个很好的、著名的曲线
plt.plot(df["Adj Close"])
第二步:通过统计数据增强你的数据
如上所述,我们需要从数据中创建更多信息供算法使用,因为它不能自行做到这一点。
我喜欢使用 ta 库,因为它使用起来非常简单,并且包含 100 多个统计计算。
安装并导入它
pip install ta
from ta import add_all_ta_features
from ta.utils import dropna
现在,如果你已经知道你想使用哪些值,你可以只选择这些值,或者我们直接将所有 100 多个值都添加到我们的数据中:
df = dropna(df) # 清理存在的 NaN 值
df = add_all_ta_features(df, open="Open", high="High", low="Low", close="Adj Close", volume="Volume")
我们做了什么?
df.columns
这应该足够了!
此外,其中仍然有很多 NaN 值,因为如果时间足够长,才能计算某些值。以我的经验,用零填充这些值效果很好,尽管有更高级的技术可以做到这一点。
df = df.fillna(0)
第三步:创建你自己的信号
现在是时候将你的奇怪交易想法转化为数字了!
让我们从经典的移动平均线交叉开始。想法如下:如果一条短期的移动平均线交叉一条较慢的移动平均线,则它表示价格上涨或下跌,具体取决于交叉的方向。
再次参考 Investopedia 以了解更多详细信息:https://www.investopedia.com/articles/active-trading/052014/how-use-moving-average-buy-stocks.asp
我们的目标是首先计算移动平均线,然后将交叉点表示为 1 和 -1,以及 0 来表示没有交叉。
创建简单移动平均线
# 创建简单移动平均线
averages = [1, 2, 5, 10, 15, 20, 25, 50, 100]
for average in averages:
df['SMA_%d' % average] = df["Adj Close"].rolling(window=average).mean()
# 仅显示移动平均线
filter_col = [col for col in df if col.startswith('SMA')]
df[filter_col].tail()
以及一些可视化:
# 生成更大尺寸的图像
plt.rcParams["figure.figsize"] = (20, 20)
for filter in filter_col:
plt.plot(df[filter], label=filter)
plt.legend()
创建交叉信号
让我们使用一个小辅助函数
def createCross(data, fastSMA, slowSMA):
fast = 'SMA_%d' % fastSMA
slow = 'SMA_%d' % slowSMA
crossname = "cross_%d_%d" % (fastSMA, slowSMA)
previous_fast = data[fast].shift(1)
previous_slow = data[slow].shift(1)
neg = ((data[fast] < data[slow]) & (previous_fast >= previous_slow))
pos = ((data[fast] > data[slow]) & (previous_fast <= previous_slow))
data[crossname] = 0
data.loc[neg, crossname] = -1
data.loc[pos, crossname] = 1
return data
现在,你可以插入自定义值,或者按照我们的示例,仅获取交叉乘积:
for fast in averages:
for slow in averages:
if fast != slow and slow > fast:
df = createCross(df, fast, slow)
这将创建一个完美的分类信号,用 1 标记向上交叉,用 -1 标记向下交叉,用 0 表示中性(无交叉)。
这只是一个你可以提供其他信号的示例。
创建百分比变化列
为了添加另一个示例,如果你尝试预测百分比变化,你需要一列显示上一时间段的百分比变化。幸运的是,使用 pandas 可以轻松做到这一点。
df["pct_change"] = df["Adj Close"].pct_change()
这对于回归模型来说是一个完美的信号!
小结
在我们添加增强功能之前,数据框只包含 5 列,对于机器学习模型来说,信息量很少!
最终,在添加统计值和我们自己的信号之后,我们的数据框已经达到了 135 个特征和列!
这对你的模型来说要好得多!
你对这个过程有什么想法?我错过了什么?请在下面评论!你想阅读更多 Justin 的文章吗?请访问我的网站了解更多信息!