अपने पायथन एल्गोरिथ्मिक ट्रेडिंग मॉडल के लिए स्टॉक डेटा में सुधार
मान लीजिए कि आप अपना खुद का एल्गोरिथमिक ट्रेडिंग मॉडल बनाने की योजना बना रहे हैं।
सबसे अधिक संभावना है कि आप अपने मॉडल और एल्गोरिथ्म के लिए केवल मूल्य (बंद) डेटा का उपयोग करेंगे, लेकिन जल्द ही आपको पता चल जाएगा कि आपका मॉडल अच्छा प्रदर्शन नहीं कर रहा है।
जल्द ही आप विशिष्ट OHLCV डेटा का उपयोग करेंगे, जो ओपन, हाई, लो, क्लोज, वॉल्यूम को संदर्भित करता है, जो पहले से ही बेहतर है, लेकिन मॉडल अभी भी पर्याप्त अच्छा प्रदर्शन नहीं कर रहा है।
आप क्या कर सकते हैं?
साथ रहने के लिए सुविधाजनक कोलैब नोटबुक: https://colab.research.google.com/drive/1ywqti1TuTDY_Z11ry0x4ITclCwxnXAeI?usp=sharing
सारांश:
https://gist.github.com/JustinGuese/019e0e71100abe6555f78c32fd0b10a9
मशीन लर्निंग ट्रेडिंग बॉट को क्या पसंद है?
टिपिकल मशीन लर्निंग एल्गोरिथ्म केवल उस डेटा के साथ काम कर सकता है जो उसे मिलता है। यह (आमतौर पर) नई विशेषताएँ या व्याख्याएँ नहीं बना सकता है जैसे “यदि वॉल्यूम बढ़ता है और कीमत का तीसरा व्युत्पन्न बढ़ता है, तो कीमत सबसे अधिक संभावना ऊपर जाएगी”, बल्कि केवल उस डेटा को “देख” सकता है जो उसे मिला है। ये गणनाएँ जैसे “यदि कीमत 100 अमेरिकी डॉलर से ऊपर है और वॉल्यूम 2000 से ऊपर है, तो कीमत सबसे अधिक संभावना ऊपर जाएगी”।
मशीन लर्निंग के नए लोग अब इस समस्या को दशकों तक प्रशिक्षण देकर या अधिक से अधिक GPU का उपयोग करके हल करने की कोशिश कर रहे हैं, लेकिन एक और अधिक कुशल तरीका यह होगा कि उस एल्गोरिथ्म को अतिरिक्त डेटा के साथ खिलाया जाए, जिससे यह अपनी गणनाओं को इन्फर करने के लिए अधिक संसाधन का उपयोग कर सके।
यह प्राप्त किया जा सकता है:
- अधिक डेटा (एक बड़ा समय अवधि) प्राप्त करना
- सांख्यिकीय मीट्रिक जोड़ना
- अपने स्वयं के सिग्नल और व्याख्याएँ जोड़ना
व्यावहारिक: अपने डेटा को बढ़ाना
पहला कदम - अपना डेटा प्राप्त करना
सबसे पहले, आइए कुछ बुनियादी OHLCV डेटा प्राप्त करें। मुझे अपनी सादगी के लिए yfinance (https://pypi.org/project/yfinance/ ) मॉड्यूल पसंद है। यह डेटा के लाइव-स्ट्रीम के बराबर नहीं है, लेकिन दूसरी ओर, यह मुफ़्त है और प्रयोगों के लिए बढ़िया है!
pip install yfinance pandas numpy matplotlib ta
उस मॉड्यूल के साथ-साथ पांडा, न्यूमपी, मैटलॉटलिब भी आयात करें
import yfinance as yf
import matplotlib.pyplot as plt
import pandas as pd
कुछ स्टॉक डेटा प्राप्त करें, अंतराल और अवधि टाइमरेंज को संदर्भित करते हैं।
interval 1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo जैसे मान स्वीकार करता है
period 1d, 5d, 1mo, 3mo, 6mo, 1y, 2y, 5y, 10y, ytd, max जैसे मान स्वीकार करता है
सभी संयोजन काम नहीं करते हैं, जैसे 1m (1 मिनट) अंतराल केवल अधिकतम 7 दिनों के साथ काम करते हैं, 1 घंटे (1 घंटा) अधिकतम 3 महीने के साथ (90d के रूप में लिखना होगा)। लेकिन आइए पहले दैनिक डेटा के साथ काम करें
df:yf.download("MSFT",period="5y",interval="1d")
df.head()
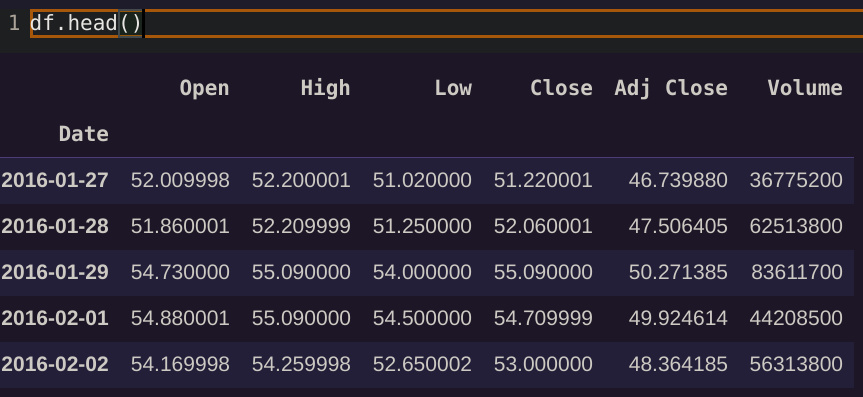
त्वरित भ्रमण: ओपन, हाई, लो, क्लोज, एडजस्ट क्लोज और वॉल्यूम क्या है? कीमत कहां है?!
स्टॉक बाजार में कोई “एक कीमत” नहीं है! आप OHLCV डेटा को समय में “बाल्टी” या “बिन” के रूप में कल्पना कर सकते हैं, जो उस विंडो में हुई सभी ट्रेडों को सारांशित करते हैं। आपको पता चलता है कि टिपिकल “लाइन” चार्ट आमतौर पर उस स्टॉक के “क्लोज” मूल्य को समय सीमा X में संदर्भित करता है, उदाहरण के लिए, जिस मूल्य पर स्टॉक का मूल्य समय सीमा के बंद होने पर था।
यदि हम दैनिक डेटा देख रहे हैं, तो “ओपन” का अर्थ है बाजार के खुलने पर औसत (!) स्टॉक मूल्य, जबकि “बंद” का अर्थ है कि बाजार के बंद होने पर स्टॉक का औसत (!) मूल्य था। यदि हम घंटे के डेटा को देखें, तो “खुला” उस घंटे की शुरुआत को संदर्भित करता है, जैसे 11 AM, और “बंद” उस घंटे के बंद होने को, यानी 11:59 am को।
इसी तरह “उच्च” उस समय सीमा में दर्ज की गई उच्चतम ट्रेड/मूल्य है, और “निम्न” सबसे कम है। वॉल्यूम उस समय सीमा में कारोबार किए गए संपत्तियों या स्टॉक की संख्या को संदर्भित करता है।
अर्थ, उदाहरण के लिए, यदि किसी कॉलम के “निम्न” और “बंद” एक-दूसरे के करीब हैं, तो हम सबसे अधिक संभावना है कि एक नीचे की ओर प्रवृत्ति देख रहे हैं क्योंकि बंद वर्तमान न्यूनतम है। इसके अलावा, यदि वॉल्यूम अधिक है, तो बहुत सारे ट्रेड चल रहे हैं, इसलिए अगर, उदाहरण के लिए, वॉल्यूम सामान्य से अधिक है, तो ऐसा लगता है कि बाजार में कुछ हो रहा है। लेकिन वैसे भी, के लिए https://www.investopedia.com/ पर जाएं, हम अब कोडिंग जारी रखेंगे!
“एडजस्ट क्लोज” क्या है?
यह महत्वपूर्ण है, क्योंकि अधिकांश एमएल एल्गोरिदम “सामान्य” बंद डेटा से बहुत भ्रमित होते हैं। यदि स्टॉक में कोई विभाजन है, तो डेटा ऐसा दिखाई देगा जैसे कीमत में बहुत तेजी से गिरावट आई है।
कारण, सीधे शब्दों में कहें, यह है कि यदि कोई स्टॉक बहुत महंगा हो जाता है, तो कंपनी स्टॉक को “विभाजित” करने का निर्णय लेती है। क्या इसका मतलब है कि मेरा निवेश आधा हो गया? बिल्कुल नहीं, आपको जो स्टॉक होल्ड कर रहे हैं, उसे दो में विभाजित करने पर आपको उतने ही स्टॉक मिलेंगे, इसलिए कागज पर आप स्टॉक का समान मूल्य रखते हैं।
दिलचस्प बात यह है कि विभाजन आमतौर पर कीमतों को बढ़ाता है (मूर्ख इंसान!), और यदि आपके मशीन लर्निंग एल्गोरिदम को कीमत में भारी गिरावट दिखती है, तो यह सबसे अधिक संभावना है कि वह उस स्टॉक को बेच देगा।
इसलिए, आपको हमेशा “समायोजित” मानों का उपयोग करना चाहिए, जिन्हें “साफ” मूल्य डेटा के रूप में समझा जा सकता है, जिसमें स्प्लिट, डिविडेंड और अन्य सभी घटनाओं को ध्यान में रखा जाता है जो डेटा के वास्तविक मूल्य को प्रभावित नहीं करती हैं। इसलिए, हमेशा अपने एल्गोरिदम के लिए समायोजित डेटा का उपयोग करने का प्रयास करें!
yfinance के मामले में, यह करना आसान है, क्योंकि हम “एडजस्ट क्लोज” के बजाय “क्लोज” का उपयोग कर सकते हैं।
डेटा प्लॉट करना
डेटा को देखते हुए, हम पहले से ही एक अच्छी, अच्छी तरह से जानी-पहचानी हुई वक्र देख सकते हैं
plt.plot(df["Adj Close"])
दूसरा चरण: सांख्यिकीय डेटा के साथ अपने डेटा को बढ़ाना
जैसा कि ऊपर कहा गया है, हमें एल्गोरिथ्म के लिए उपयोग करने के लिए अपने डेटा से और अधिक जानकारी बनानी है, क्योंकि यह ऐसा स्वयं नहीं कर सकता है।
मुझे ta (https://github.com/bukosabino/ta ) लाइब्रेरी पसंद है, क्योंकि यह फिर से उपयोग करने में बहुत आसान है और इसमें 100+ सांख्यिकीय गणनाएँ हैं।
इसे स्थापित करें और इसके साथ आयात करें
pip install ta
from ta import add_all_ta_features
from ta.utils import dropna
अब यदि आप पहले से जानते हैं कि आप किन मानों का उपयोग करना चाहते हैं, तो आप केवल इन्हें चुन सकते हैं, या हम अपने डेटा पर सभी 100+ को तोड़ सकते हैं:
df:dropna(df) # मौजूद नैन को साफ करें
df:add_all_ta_features(df,open="Open", high="High", low="Low", close="Adj Close", volume="Volume")
तो हमने क्या किया है?
df.columns
Index(['Open', 'High', 'Low', 'Close', 'Adj Close', 'Volume', 'volume_adi',
'volume_obv', 'volume_cmf', 'volume_fi', 'volume_mfi', 'volume_em',
'volume_sma_em', 'volume_vpt', 'volume_nvi', 'volume_vwap',
...
])
अब इसके लिए पर्याप्त होना चाहिए!
इसके अलावा, वहाँ अभी भी बहुत सारे नैन हैं, क्योंकि कुछ मानों की गणना केवल तभी की जाती है जब पर्याप्त समय बीत गया हो। मेरे अनुभव में, उन्हें शून्य से भरना काफी अच्छा काम करता है, भले ही इसके लिए और उन्नत तकनीकें हों।
df:df.fillna(0)
तीसरा चरण: अपने खुद के संकेत बनाना
अब यह आपके अजीब व्यापारिक विचारों को संख्याओं में बदलने का समय है!
आइए क्लासिक मूविंग एवरेज क्रॉस से शुरू करें। विचार इस प्रकार है: यदि एक छोटी मूविंग एवरेज धीमी मूविंग एवरेज को पार करती है, तो यह या तो कीमत में वृद्धि या गिरावट का संकेत देती है, क्रॉस की दिशा के आधार पर।
विवरण के लिए फिर से इन्वेस्टोपीडिया देखें: https://www.investopedia.com/
हमारा लक्ष्य पहले SMA की गणना करना है, और फिर क्रॉस को 1 और -1, और 0 को कोई क्रॉस नहीं दिखाने के लिए तैयार करना है।
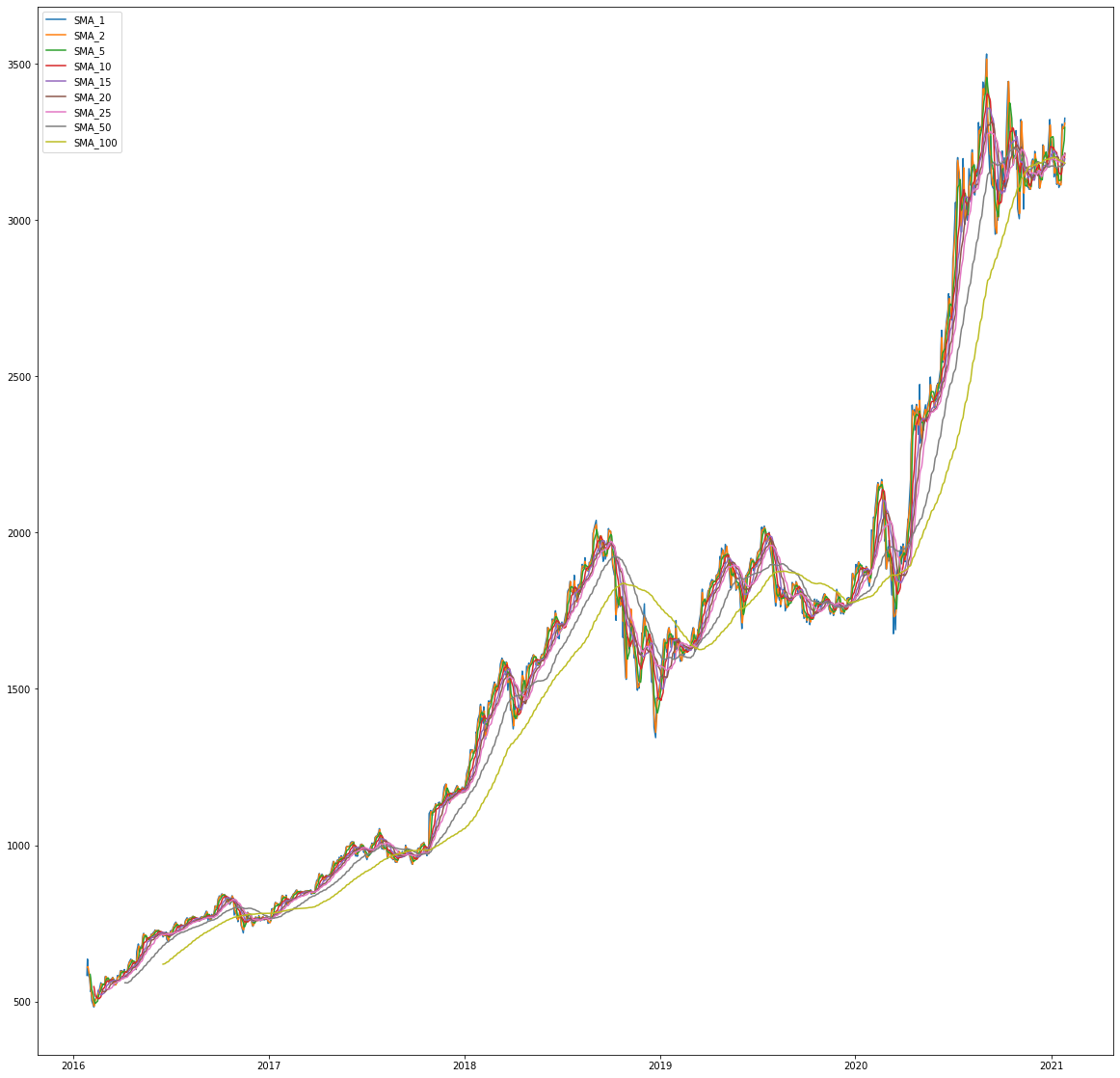
सरल चलते औसत बनाना
# सरल चलती औसत बनाना
averages:[1,2,5,10,15,20,25,50,100]
for average in averages:
df['SMA_%d'%average]:df["Adj Close"].rolling(window=average).mean()
# केवल SMA को विजुअलाइज करें
filter_col:[col for col in df if col.startswith('SMA')]
df[filter_col].tail()
और कुछ विजुअलाइजेशन:
# बड़े आंकड़े प्राप्त करें
plt.rcParams["figure.figsize"]:(20,20)
for filter in filter_col:
plt.plot(df[filter],label=filter)
plt.legend()
एक क्रॉसओवर सिग्नल बनाना
आइए एक छोटी सहायक फ़ंक्शन का उपयोग करें
def createCross(data,fastSMA,slowSMA):
fast:'SMA_%d'%fastSMA
slow:'SMA_%d'%slowSMA
crossname: "cross_%d_%d"%(fastSMA,slowSMA)
previous_fast:data[fast].shift(1)
previous_slow:data[slow].shift(1)
neg:((data[fast] < data[slow]) & (previous_fast >= previous_slow))
pos:((data[fast] > data[slow]) & (previous_fast <= previous_slow))
data[crossname]:0
data.loc[neg,crossname]:-1
data.loc[pos,crossname]:1
return data
और अब आप या तो अनुकूलित मान डाल सकते हैं या हमारे उदाहरण का पालन कर सकते हैं और केवल क्रॉस उत्पाद ले सकते हैं:
for fast in averages:
for slow in averages:
if fast != slow and slow > fast:
df:createCross(df,fast,slow)
इसने एक आदर्श वर्गीकरण सिग्नल बनाया जो ऊपर की ओर क्रॉस को 1 और नीचे की ओर क्रॉस को -1 के साथ संकेत करता है, 0 एक तटस्थ (कोई क्रॉस नहीं) होता है।
यह आपके द्वारा प्रदान किए जा सकने वाले अन्य संकेतों का केवल एक उदाहरण है।
प्रतिशत परिवर्तन कॉलम बनाना
और एक और उदाहरण जोड़ने के लिए, यदि आप प्रतिशत परिवर्तन की भविष्यवाणी करने का प्रयास कर रहे हैं, तो आपको पिछली समय अवधि के प्रतिशत परिवर्तन दिखाने वाला एक कॉलम की आवश्यकता होगी। पांडा का उपयोग करके इसे आसानी से किया जा सकता है।
df["pct_change"]:df["Adj Close"].pct_change()
#आउटपुट
Date
2021-01-21 0.013363
2021-01-22 -0.004463
2021-01-25 0.000538
2021-01-26 0.009754
2021-01-27 -0.010484
Name: pct_change, dtype: float64
एक प्रतिगामी मॉडल के लिए यह एकदम सही संकेत है!
सारांश
इससे पहले कि हम अपने संवर्द्धन जोड़ते, डेटाफ़्रेम में केवल 5 कॉलम थे, मशीन लर्निंग मॉडल के लिए बहुत कुछ नहीं!
अंत में, सांख्यिकीय मान और अपने स्वयं के संकेत जोड़ने के बाद, हम पहले से ही अपने डेटाफ़्रेम के 135 फ़ीचर और कॉलम तक पहुँच गए!
यह आपके मॉडल के लिए बहुत बेहतर है!
इस प्रक्रिया के बारे में आपका क्या विचार है? क्या मुझे कुछ याद आया? नीचे टिप्पणी करें! क्या आप जस्टिन द्वारा और लेख पढ़ना चाहते हैं? अधिक जानकारी के लिए मेरी वेबसाइट पर जाएँ!