I divided this post into the “Why did I do it” and the “Technical How To”. If you want to skip the “Why” part, feel free to directly jump to the Technical part.
Why should I deploy a machine learning model in AWS Lambda?
1. Reliability: The algorithm will execute independently of other systems, updates, …
2. Performance Efficiency: I can run several algorithms on one (small) system, independent from each other.
3. Cost Savings: AWS allows for 3,2 million compute-seconds per month, basically letting me run all my algorithms for free.
I have been searching for a way to first make sure my investment bot surely executes because a failed execution might cost a lot of money if a trade is not canceled promptly if it goes in the wrong direction. Additionally, I wanted to avoid letting my computer run all the time and to make sure several algorithms could run next to each other, without influencing or delaying their execution.
Furthermore, it is a nice thought to have an investing algorithm run without worrying about operating system updates, hardware failures, and power cuts, etc, which is the general advantage of serverless technologies.
Right now, I can run several variations of the algorithm to test out alterations of the algorithm and can be sure that it will run. Another nice thing? AWS offers around 1 Million free Lambda calls, which lets me run the whole architecture in its free tier contingent.
The investing algorithm
I am going to explain the algorithm in more depth in another post on my website www.datafortress.cloud, but my typical investment algorithm setup consists of:
- Testing the algorithm using Backtrader, an open-source backtesting framework written in python
- Converting the successful algorithm into a single python file containing a run() method that returns which investments have been done
- Transferring the python file to AWS Lambda, where I am calling the run() function with AWS Lambda’s lambda_handler function
In this example algorithm, I take investment decisions depending on if the current price is above or below the trendline predicted by Facebook’s prophet model. I have taken ideas from Sean Kelley, who wrote a Backtrader setup on how to utilize prophet with Backtrader.
My stock universe in this setup is calculated by choosing the top 20 stocks out of the SPY500 index, which achieved the highest return in the past X timesteps.
The data source is Yahoo finance, using the free yfinance library, and as my algorithmic broker of choice, I have chosen Alpaca.markets.
In my setup, the algorithm will execute once per day at 3 p.m. or every 15 minutes during trading hours.
The problems deploying Facebook Prophet to AWS Lambda
AWS Lambda comes with some python libraries preinstalled, but as many of you might know, this is by default quite limited (which is reasonable for Lambda’s promise). Still, Lambda allows for private packages to be installed which is quite easy for smaller packages (see the official documentation) but becomes a little more complicated if dealing with packages that exceed 250 Mb in size. Unfortunately, Facebook’s prophet model exceeds this boundary, but luckily Alexandr Matsenov solved this issue by reducing the package size and Marc Metz handled compilation issues to make it run on AWS Lambda.
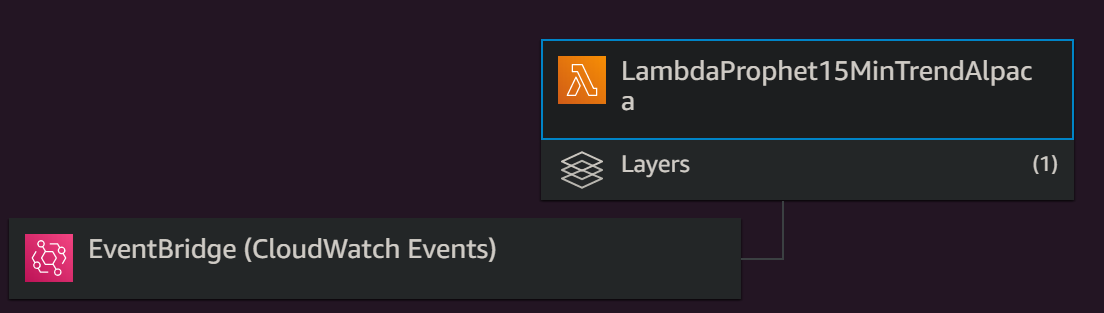
Non-default libraries can be added to AWS Lambda by using Layers, which contain all the packages needed. If a layer is imported, you can simply import the packages in your python function as you would do it in your local setup.
How to (technical)
Finally, let me explain how exactly you can achieve this. See this TLDR for the impatient types, or the more detailed version below.
TLDR;
- You will need a Lambda Layer, upload mine (download) containing Prophet, yfinance, … to an S3 bucket (private access)
- Select AWS Lambda, create a function, add a layer and paste in your S3 object URL
- Paste your lambda_function.py into the Lambda Editor (or use mine)
- Set up your Environment variables (optional)
- Either run it manually by clicking “test” or head over to CloudWatch -> Rules -> Create Rule and set up “Schedule Execution” to run it in a specified time interval
Detailed Explanation:
1. Creating a custom layer for AWS Lambda
You can either use my Lambda layer containing Facebook Prophet, NumPy, pandas, alpaca-trading-API, yfinance (GitHub) or compile your own using the explanation given by Marc.
Using my Lambda Layer
- Download the zip file from my Github repo containing all packages (Link).
- As you can only directly upload layers to Lambda until the size of 50 Mb, we will first need to upload the file to AWS S3.
- Create a bucket and place the downloaded zip file into it. Access can remain private and does NOT need to be public! Copy the URL to your file (e.g. https://BUCKETNAME.s3.REGION.amazonaws.com/python.zip).
- Log into AWS and go to Lambda -> Layers (EU central Link).
- Click “Create layer”, give it a matching name and select “Upload a file from Amazon S3”, and copy the code of step 3 into it. As Runtimes select Python 3.7. Click create.
Compiling your own Lambda Layer
Please follow the instructions of Marc.
2. Setting up an AWS Lambda function
- Open the Lambda Function Dashboard (EU central Link) and click “Create function”
- Leave the “Author from scratch” checkbox as is and give it a fitting name.
- In “Runtime”, select Python 3.7, leave the rest as is and click “Create function”.
- In the overview of the “designer” tab, you will see a graphical representation of your Lambda function. Click on the “layers” box below it and click “Add a layer”. If you correctly set up the layer, you will be able to select it in the following dialogue. Finally, click on “Add”.
- In the “designer” tab, select your Lambda Function. If you scroll down, you will see a default python code snippet in a file called “lambda_function.py”. If you have structured your code the same as mine (Link), you can execute your function with the run() function. If a Lambda function is called, it will execute the lambda_handler(event, context) function from which you could e.g. call the run() function. Of course, you can rename all files and functions, but for the simplicity of this project, I left it as it is.
- Feel free to just paste in my function and test it.
- Clicking on “Test” should result in successful execution, otherwise, it will state the errors in the dialogue.
3. Using environment variables in AWS Lambda
You should never leave your user and password as cleartext in your code, which is why you should always use environment variables! Luckily, Lambda uses them as well, and they can easily be called with the python os package. E.g. in my script I am calling the user variable with os.environ[‘ALPACAUSER’]. The environment variables can be set up in the main Lambda function screen when scrolling down below your code editor.
4. Trigger AWS Lambda functions at a specified time interval
The concept of serverless and AWS Lambda is built on the idea that a function is executed when a trigger event happens. In my setup, I wanted the function to be called e.g. every 15 minutes during trading hours, Monday to Friday. Luckily, AWS offers a way to trigger an event without the need to run a server, using the CloudWatch service.
- Head over to CloudWatch (EU central Link).
- In the left panel, select “Events” and “Rules”.
- Click on “Create Rule”, and select “Schedule” instead of “Event pattern”. Here you can use the simple “Fixed-rate” dialogue, or create a cron expression. I am using https://crontab.guru/ (free) to create cron expressions. My cron expression for the abovementioned use case is “0/15 13-21 ? * MON-FRI *”.
- In the right panel, select “Add Target” and select your Lambda function. It will automatically be added to Lambda.
- Finally click on “Configure details”, give it a name, and click on “Create rule”.
5. (optional) Log Analysis, Error Search
If you have made it to this part, you should be done! But if you want to check if everything worked, you can use CloudWatch to have a look at the outputs of the Lambda functions. Head over to CloudWatch -> Logs -> Log groups (EU central Link) and select your Lambda function. In this overview, you should be able to see the output of your functions.
If you have liked this post leave a comment or head over to my blog www.datafortress.cloud to keep me motivated 😊.


